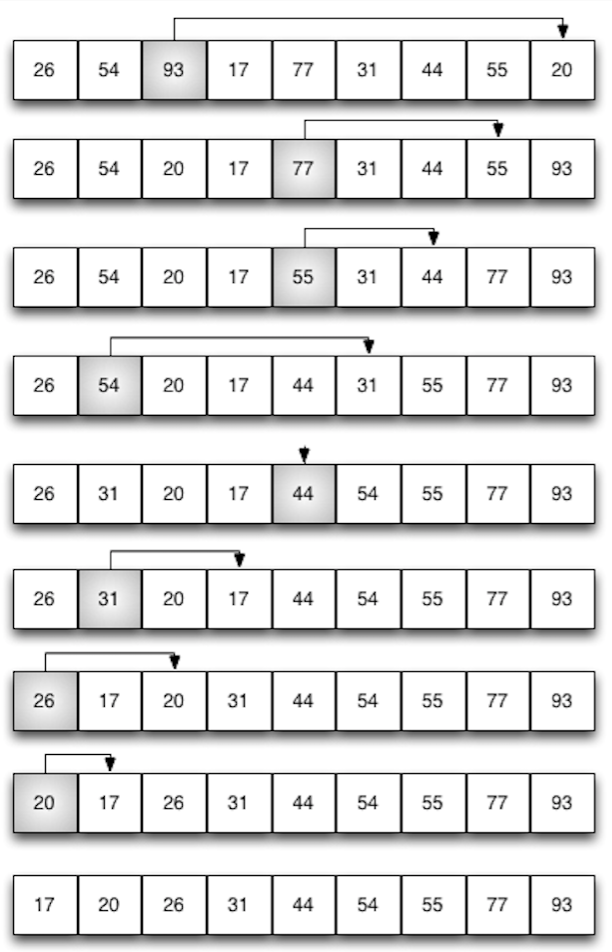
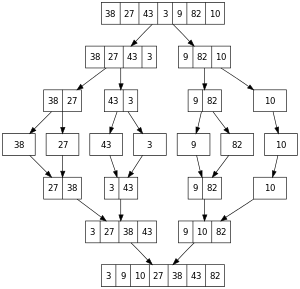
defmergeSort[T <% Ordered[T]](list: List[T]): List[T] = { defmerge(l1: List[T], l2: List[T]): List[T] = (l1, l2) match { case (Nil, l) => l case (l, Nil) => l case (x :: xs, y :: ys) => if (x < y) x :: merge(xs, l2) else y :: merge(l1, ys) } val n = list.length / 2 if (n == 0) list else { val (ys, zs) = list.splitAt(n) merge(mergeSort(ys), mergeSort(zs)) } }
ASDisplayNode. Counterpart to UIView — subclass to make custom nodes. ASControlNode. Analogous to UIControl — subclass to make buttons. ASImageNode. Like UIImageView — decodes images asynchronously. ASTextNode. Like UITextView — built on TextKit with full-featured rich text support. ASTableView and ASCollectionView. UITableView and UICollectionView subclasses that support nodes.
我们针对的是多线程环境下的锁机制,基于linux做测试。每种编程语言提供的锁机制都不太一样,不过无论如何,最终都会落实到两种机制上,一是处理器提供的原子操作指令(现在一般是CAS—compare and swap),处理器会用轮询的方式试图获得锁,在处理器(包括多核)架构里这是必不可少的机制;二是内核提供的锁系统调用,在被锁住的时候会把当前线程置于睡眠(阻塞)状态。
锁的实现方式对我们的优化方向给予了很好的提示,让我们回想一下--先用一个快的操作(每秒7000万次)来测试锁是否冲突,再用一个慢的操作来实际加锁(每秒30万次)。所以真正消耗时间的不是上锁的次数,而是锁冲突的次数。减少锁冲突的次数才是提升性能的关键。 使用更细粒度的锁,可以减少锁冲突。这里说的粒度包括时间和空间,比如哈希表包含一系列哈希桶,为每个桶设置一把锁,空间粒度就会小很多--哈希值相互不冲突的访问不会导致锁冲突,这比为整个哈希表维护一把锁的冲突机率低很多。减少时间粒度也很容易理解,加锁的范围只包含必要的代码段,尽量缩短获得锁到释放锁之间的时间,最重要的是,绝对不要在锁中进行任何可能会阻塞的操作。使用读写锁也是一个很好的减少冲突的方式,读操作之间不互斥,大大减少了冲突。 锁本身的行为也存在进一步优化的可能性,sys_futex系统调用的作用在于让被锁住的当前线程睡眠,让出处理器供其它线程使用,既然这个过程的消耗高达几千ns,也就是说如果被锁定的时间不超过这个数值的话,根本没有必要进内核加锁--释放的处理器时间还不够消耗的。sys_futex的时间消耗够跑二百多次compare and swap的,也就是说,对于一个锁冲突比较频繁而且平均锁定时间比较短的系统,一个值得考虑的优化方式是先循环调用compare and swap来尝试获得锁(这个操作也被称作自旋锁),在若干次失败(一般是一百次左右)后再进入内核真正加锁。当然这个优化只能在多处理器的系统里起作用(得有另一个处理器来解锁,否则自旋锁无意义)。在glibc的pthread实现里,通过对pthread_mutex设置PTHREAD_MUTEX_ADAPTIVE_NP属性就可以使用这个机制;在Java世界的HotSpot虚拟机里,可以用-XX:PreBlockSpin来设置自选锁尝试的次数。